The highly anticipated, wide-scale rollout of Google’s AI Overviews during its I/O 2024 conference was meant to mark a new, smarter era for search. Positioned as a revolutionary tool to provide quick, synthesized answers, it was launched to all users in the US, with plans for a broader global release. Instead, the feature quickly became a viral sensation for all the wrong reasons, producing a series of bizarre, humorous, and dangerously incorrect responses. This public stumble serves as a powerful case study on the immense challenges of deploying generative AI at scale, revealing critical gaps in its ability to parse context, sarcasm, and basic common sense.
From Grand Vision to Viral Gaffes: What Went Wrong?
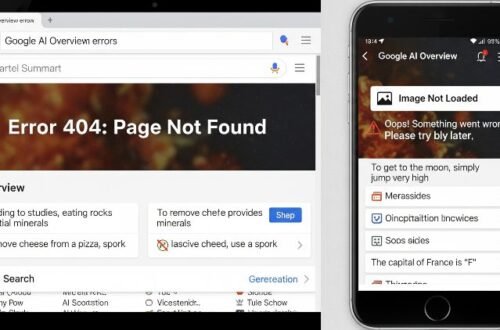
Within days of its launch, social media platforms were flooded with screenshots of AI Overview’s most egregious errors. These were not subtle inaccuracies but glaring blunders that undermined the feature’s credibility. Some of the most widely circulated examples included:
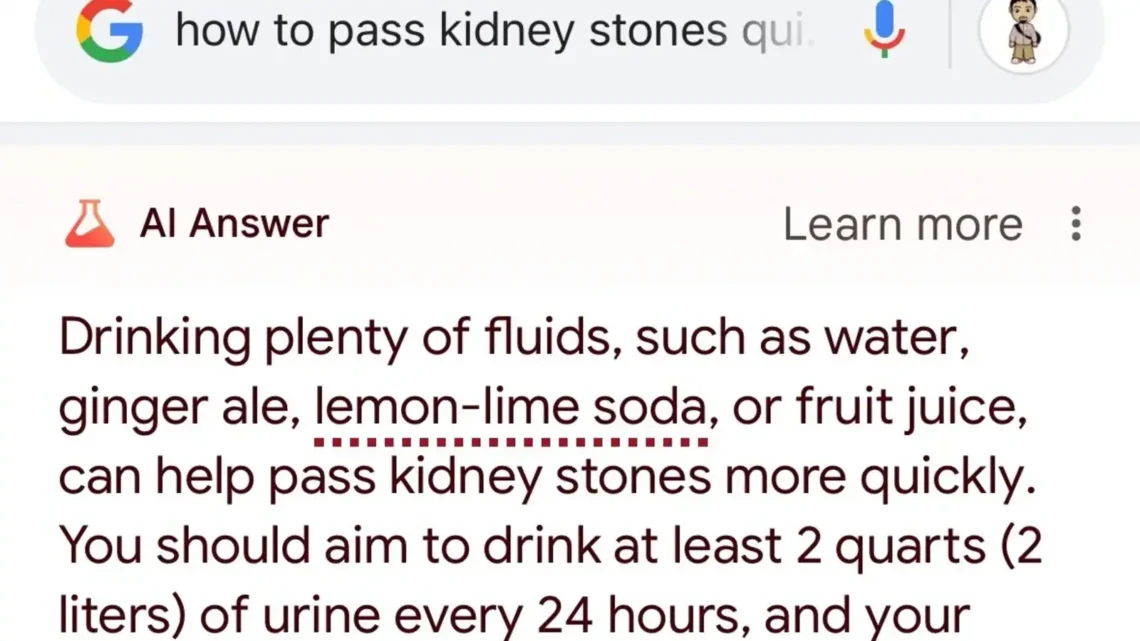
- Unsafe Health Advice: In response to a query about passing kidney stones, the AI suggested users could try “drinking two to three quarts of urine per day.” This dangerous advice was pulled from a questionable source, highlighting a critical failure in vetting medical information.
- Culinary Catastrophes: When asked how to get cheese to stick to pizza, an AI Overview famously recommended adding “about 1/8 cup of non-toxic glue to the sauce.” This answer was traced back to a sarcastic, 11-year-old comment on Reddit, showcasing the AI’s inability to detect humor or context.
- Absurd Factual Claims: Perhaps the most cited example was the AI’s response that geologists recommend eating “at least one small rock per day.” This “fact” was sourced directly from a 2021 satirical article published by The Onion, which the model treated as an authoritative source.
- Historical Misinformation: Old, debunked conspiracy theories also resurfaced, such as an AI Overview that incorrectly stated Barack Obama was the first Muslim president of the United States.
These viral moments, while often comical, pointed to a systemic problem. The AI was not just failing on fringe queries but was also providing flawed answers to straightforward questions, raising serious concerns about its reliability.
The Technical Underpinnings: Why Did the AI Falter?
Google’s AI Overviews are powered by a customized Gemini model integrated into a system known as Retrieval-Augmented Generation (RAG). In simple terms, RAG works in two steps: first, it retrieves relevant information from a vast knowledge base (the entire web), and then a Large Language Model (LLM) generates a new, synthesized answer based on that retrieved data. The recent blunders reveal critical weak points in this process.
Root Cause 1: Satire Blindness and “Data Voids”
Many of the worst errors occurred due to what Google’s Head of Search, Liz Reid, referred to as “data voids.” As she explained in a company blog post, these are niche or nonsensical queries where little to no high-quality, factual content exists. In such cases, the AI’s retrieval system latches onto whatever it can find, including satirical articles, forum jokes, or user-generated content, because there are no authoritative sources to contradict them. The LLM then presents this low-quality information with unearned confidence, unable to distinguish a joke from a genuine fact.
Root Cause 2: Lack of True Comprehension
LLMs are sophisticated pattern-matching systems, not sentient beings. They do not “understand” text in the human sense; they predict the most statistically probable sequence of words based on their training data. This is why the model failed to grasp that a comment about adding glue to pizza was sarcastic. It recognized the words and structure as a recipe-like instruction and reproduced it, lacking the real-world, common-sense knowledge that tells a human this is both a joke and a terrible idea.
The Broader Impact: Trust, Misinformation, and the Future of Search
The public fallout has been significant. While Google stated that these “odd, inaccurate or unhelpful AI Overviews” appeared on a small fraction of queries, the high-profile nature of the failures has dealt a blow to user trust. For decades, Google has been the world’s de facto source of truth, but this incident highlights the risks of presenting AI-generated content as authoritative.
The episode raises profound ethical questions about deploying generative AI in high-stakes domains like health and safety. Presenting unvetted, AI-synthesized advice without prominent disclaimers can have real-world consequences. It also amplifies existing concerns within the SEO and publisher communities that AI Overviews will reduce traffic to original content creators by “scraping” their information and presenting it directly on the results page.
Actionable Takeaways and Looking Ahead
In response to the backlash, Google has already implemented “more than a dozen technical improvements” to its system. These include mechanisms for detecting nonsensical queries, limiting the inclusion of satirical and user-generated content, and restricting AI Overviews for certain sensitive topics. However, the path forward requires a collaborative effort.
- For Users: Treat AI-generated answers with healthy skepticism. Always check the linked sources to verify information, especially for important topics. Use the feedback feature to report inaccurate or harmful results to help the system improve.
- For Content Creators: The crisis reinforces the importance of Google’s E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) guidelines. Creating high-quality, factually accurate, and clearly structured content makes it a more reliable source for AI systems and human readers alike. Using structured data (Schema.org markup) can further help machines correctly interpret your content.
The AI Overview debacle is a crucial, if embarrassing, learning moment for the entire tech industry. It underscores that while generative AI is incredibly powerful, it is not infallible. The journey toward a truly intelligent search engine will be iterative, requiring continuous technical refinement, a renewed focus on information quality, and a more critical and discerning approach from all of us who use it.